
Pilot Study for H2O Driverless AI
Automatic Machine Learning, or AutoML, has becoming an increasingly hot topic in data science world today. Many people would be fascinated by the concept of “building models automatically”, where one can just feed the data into some AutoML toolkit, and then get the ML model ready for deployment within minutes. - But is it really the case? With this question in mind, I started with some explorations on the available AutoML solutions in market.
There are quite a few players in the field of AutoML, including the big names such as Google and IBM, as well as various start-ups that are providing their unique Auto ML solutions. Among all the players, H2O.ai and DataRobot are some of the most popular ones among the others, given the maturity of their solutions and the flexibilities to integrate with customers’ existing data eco-systems. In this post, I have done a pilot study for the AutoML solution from H2O.ai, named H2O Driverless AI (H2O DAI), would love to share some of my learnings along the way.
H2O DAI Key features
There are a few key features H2O DAI provides that brings benefits to users.
1.User Friendly GUI:
H2O DAI has a very user friendly GUI with both basic and expert settings, making it useful for both general business users and experienced data scientists.
2.Various feature transformers and ML Algorithms Support:
H2O DAI supports various feature transformers and ML algorithms. Most importantly, the feature selection and model hyper-parameter tuning processes are all taken care of automatically in the pipeline.
3.MLI(Machine Learning Interpretability) Feature:
With increasing demands for explainable AI, the MLI functions H2O provides might be helpful in some use cases. H2O DAI provides several options to increase the transparency and accountability of complex models, including Leave-one-covariate-out (LOCO) local feature importance, partial dependence plots, decision tree surrogate models, etc. For more details on MLI, you may refer to this doc.
4.Custom Recipe Support:
No one single tool can cover all the potential use cases, thus the flexibility of customization is important. With custom recipe function enabled, users have the freedom to upload custom algorithms or scorers code scripts into H2O DAI to be used for model training.
5.Auto Doc(Automatic Documentations):
This is a desirable feature for model applications under strict regulatory environment, where it is usually a must to document down the feature selection, parameter tuning steps in details. With Auto-doc function, some of the information could be automatically captured, saving a lot of time on documentations later on.

H2O DAI Modelling Workflow
The general workflow of H2O DAI is actually similar to the regular model building process. Below is a diagram showing the overall workflow:
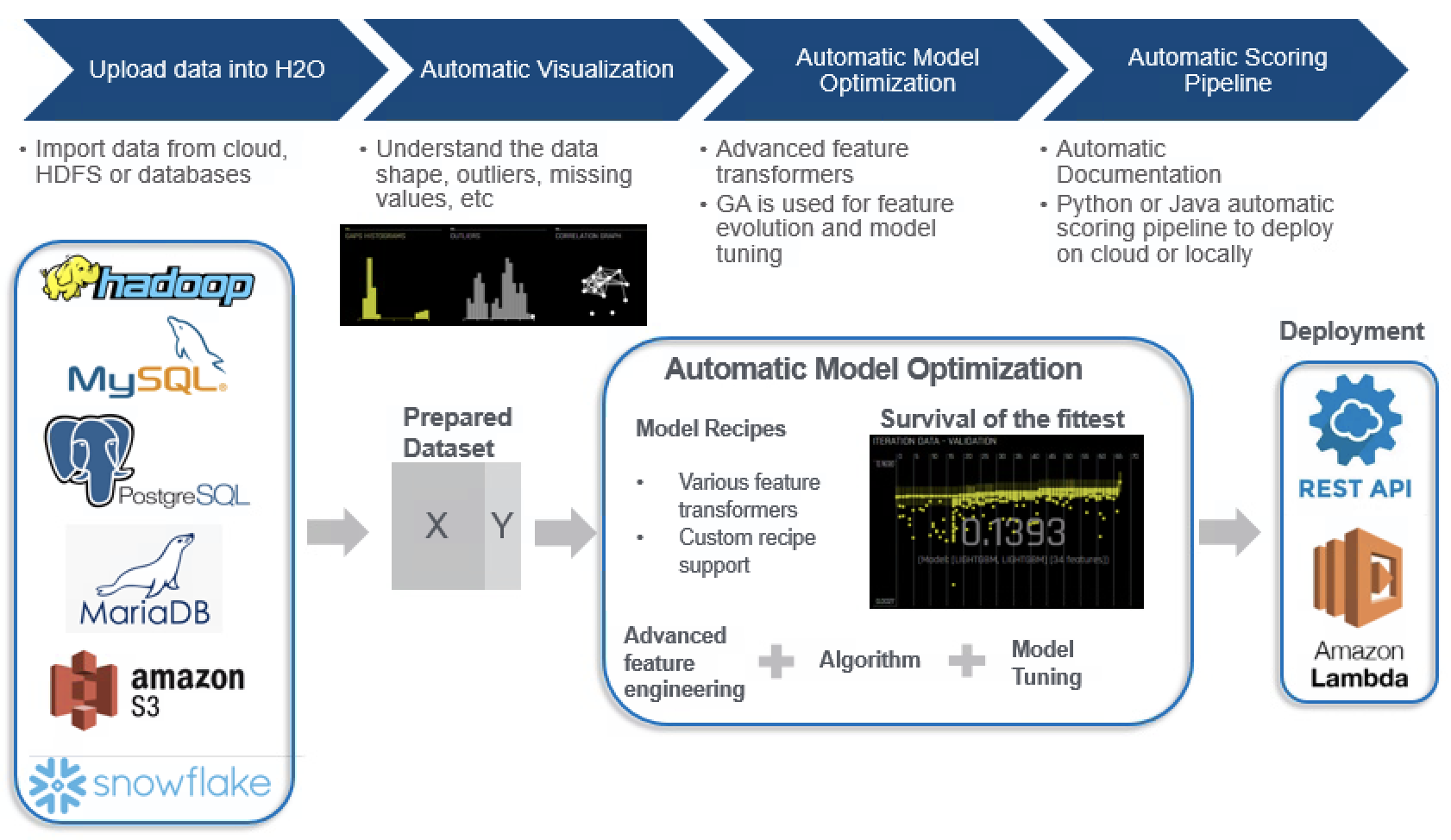
1.Importing data into H2O:
First of all, users need to import the data to H2O DAI. There are actually plenty of options for data importing, including cloud data source like Amazon S3, relational DB connections such as MySQL and MariaDB, as well as distributed file systems like HDFS.
On another side note, before importing the data into H2O, certain level of feature engineering works may still be necessary. Although some high level data cleaning actions would be applied by H2O DAI before entering the modelling step, it is still valuable to do some sanity checks. For instance, you might want to remove certain features based on business understanding, or you want to do the up-sampling or down-sampling yourself before feeding the data into H2O DAI, etc.
2.Data Visualization:
Upon uploading the data into H2O DAI, there are a few options handy to help users get a feel about the data, including automatic visualizations, data summaries (metrics such as min, max, missing values for each individual features). This feature could also serve as a sanity check step to confirm if there are any features with high percentages of missing values, or if certain features are having a high correlation with each other.
3.Automatic Model Optimization:
At this stage, H2O DAI would run Genetic Algorithm for different combinations of features, feature transformers and ML models based on the experimental settings (more details on this later), and record down the best performing model in the end.
4.Model Documentation and Deployment:
After H2O DAI finishes the modelling process, model documentation will be generated to record down the key modelling steps. In terms of model deployment, H2O could automatically generate the scoring pipeline in both Java and Python to be deployed under REST API framework. There are also options to deploy the model directly into cloud platforms, such as Amazon Lambda.
H2O Experiment Configurations
One of the key steps to build good models in H2O DAI is to make proper selections under the experiment configuration page. As show on the diagram below, there are a few parameters that users need to input, including training/testing data selections, target variable seletion, etc. There are three main tuning knobs in the configuration page that would largely decide on what the final model would be like, that is Accuracy, Time and Interpretability. For each of the knob, users can choose its value from 1 to 10.
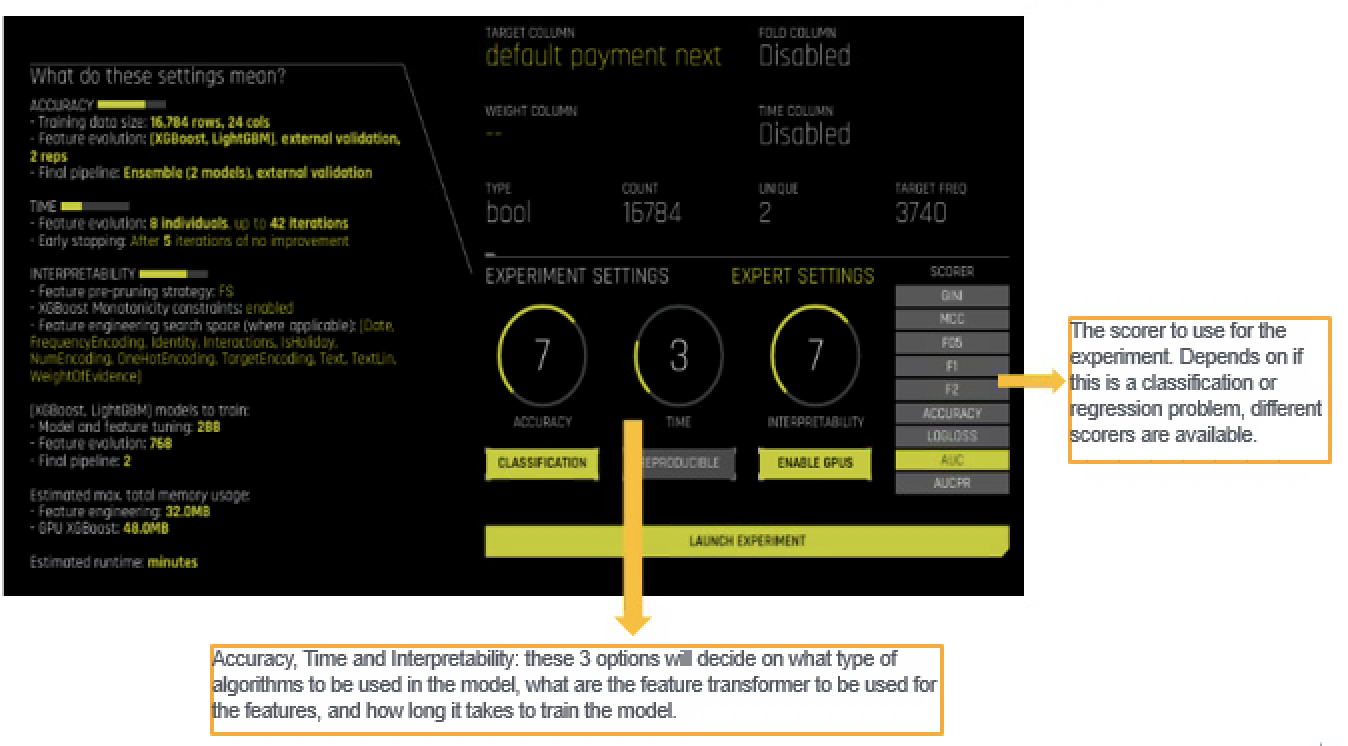
1.Accuracy:
When adjusting the accuracy knob value, the way H2O DAI performs evolution and ensemble will be adjusted. With low accuracy value, users shall generally expect single model as the final output, whereas with higher accuracy, each independent model will evolve independently and then be part of the final ensemble model. Meanwhile, H2O DAI will also use higher number of folds validation for better model generalizations.
2.Time:
As the name suggests, it is used to configure how much time users give for H2O DAI to run optimizations. With a higher value configured for time knob, more iterations of trainings and validations would be conducted.
3.Interpretability:
Interpretability will largely decide the complexity of the final model. With higher Interpretability value configured, the final model tends to have lower level or no ensemble done, and it tends to use more basic feature transformers and ML models.
For greater details on how changing each individual knob values, you may refer to the official documentations here. One thing to note, the three knob values are not strictly independent from each other. For instance, both the accuracy and interpretability knob value will decide on the ensemble efforts in the final model. Therefore, there is really no golden rules here about how to choose the best knob values - most likely some trail and errors expected here. Luckily, H2O makes this step more intuitive for users by giving a preview section (as shown in the diagram earlier, “What do these settings mean?” in the left hand side) It will give users a higher level overview on what to expect in the final model when changing each individual knob values.
In case you want more flexibility on what feature transformers to use, or what scorers to select for the final model, H2O DAI does provide the options under “Expert Settings” pages. Inside, users can have a more customized selection of what features transformers to include, what ML models to use or even load in some pre-trained neural network models for NLP related tasks. In short, the expert settings could be more useful if users have some experiences in model building previously.
H2O DAI Model Deployment
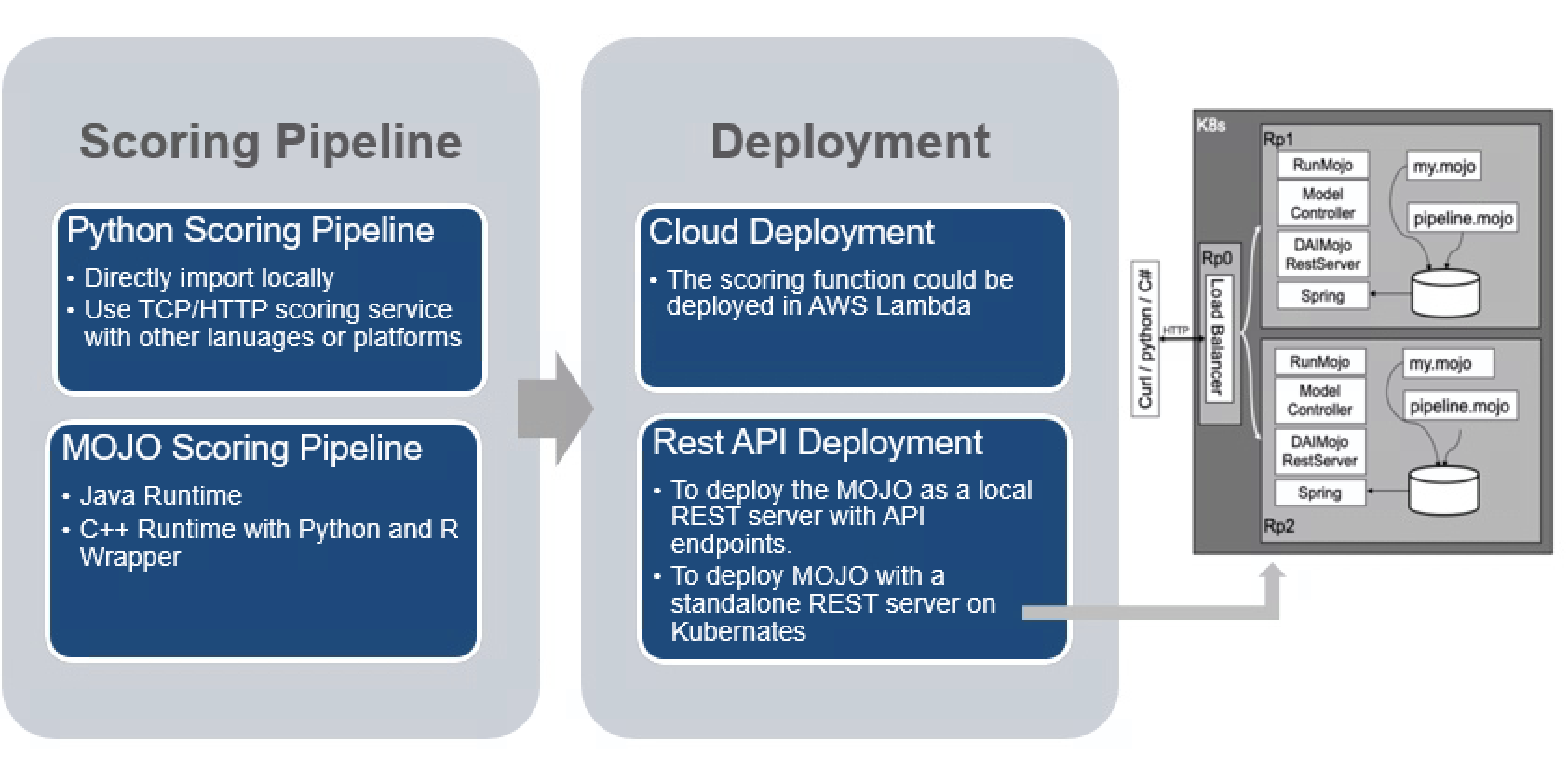
After obtaining model, the next step is to deploy it and put it into use in production. H2O DAI does have the option to export the scoring pipeline both in Python and as a MOJO (Model Object, Optimized).
The python scoring pipeline is a more straight forward extension of ML model, where you have the option to deploy it locally for testing purpose, or you can use TCP/HTTP scoring service for other languages and platforms.
The MOJO scoring pipeline makes use of the MOJO, which is an H2O-optimized version of POJO. When dealing with larger datasets and more complex models, MOJO objects generally consume smaller disk space with a better speed performance. It can be used in Java programs naturally, but users can also use R/Python to call the MOJO object to make predictions.
With the scoring pipeline in place, there are options to deploy the model in cloud (AWS Lambda is the recommend one by H2O), but the more popular option might be the REST API deployment with MOJO. However, likely there are still some man days required to integrate the model into production - so in a sense the model deployment part is not fully automated by H2O DAI yet.
Things to take note
I have tried to use H2O DAI to build models and compared its performance with hand built models. In general, H2O DAI is able to achieve comparable, if not better performance for most use cases if configured properly. In fact, H2O DAI includes various ML models, feature transformers and is able to run through so many different combinations of features, models and hyper parameters, and ensemble the best performing models to further boost up the model scores. As a result, H2O DAI does show the advantages of getting better prediction scores, statistically, in most cases. Having said that, there are still some areas where you need to pay attention to when considering to use this AutoML toolkit for production. Just to name a few:
1.Be aware of things that are not automated:
While H2O DAI has already done a good job to automate a lot of time consuming processes for building models, there are still things that users need to handle manually. One example might be the feature engineering part, although there are quite a few feature transformers available in H2O, they might not happen to cover what you need exactly. Thus I believe similar to building regular models, data cleaning and feature engineering remain as important steps even with H2O DAI.
2.When business understanding and explainability matters:
While H2O DAI doing computations internally, the optimization is purely driven by improving the scoring function statistically. There could be cases where a feature transformer gets applied and leads to overall improvements in model scores, but it might not make much sense from business perspective.
For instance, H2O DAI might choose to apply a log transform for variable that represent the past three months transaction counts of customers - would that feature make sense from business point of view? There are no strict right or wrong answers for this, but alignments have to be made with relevant stakeholders, especially for the model reviewers who are typically more conservative for “automatic processes”.
3.Extra efforts still required for production:
Model deployment and monitoring is another critical component in ML modelling life cycle. As we mentioned earlier, though H2O DAI could generate the scoring pipeline automatically, there are still some integration efforts required before moving it into production, such as setting up a REST API with the scoring pipeline, make data connections with on premise database, setting up the tracking system to monitor the model performances regularly, and so on. All these steps still need to be planned and tested outside H2O DAI at the moment.
Having said that, H2O DAI is evolving rapidly along the way. I would not be surprised that given some time, some of the mentioned issues can be resolved or improved significantly.
Useful Reference
H2O DAI official website is a good starting point to get started with the tool. If you want to have a hands-on experience with H2O DAI before purchasing the licence, H2O also offers a free 21-day trail once you sign up for it.
Another documentation that helped me a lot is the PDF version of H2O DAI documentation. It contains more of less similar contents with the online user manual, but I felt it gave a more structured view on how to understand and learn H2O in a more systematic way.
I hope this post may help someone who is interested in H2O DAI as the potential AutoML solution. Thanks for reading!